Firefox Quantum 发布在即。它带来了许多性能改进,包括从 Servo 引入的的极速 CSS 引擎。
但 Servo 中的很大一块技术尚未被 Firefox Quantum 引入,虽然已经为期不远。这就是WebRender,它是 Quantum Render 项目的一部分,正被添加到 Firefox 中。

WebRender 以极速著称,但它所做的并非加速渲染,而是使渲染结果更加平滑。
依靠 WebRender,我们希望应用程序以每秒 60 帧(FPS)乃至更快的速度运行:无论显示器有多大,页面每帧发生多少变化。这是可以做到的。在 Chrome 和当前版本的 Firefox 中,某些页面卡到只有 15 FPS,而使用 WebRender 则能达到 60 FPS。
WebRender 是如何做到这些的呢?它从根本上改变了渲染引擎的工作方式,使其更像 3D 游戏引擎。
一起来看看这话怎么说。
渲染器的工作
在关于 Stylo 的文章中,我讨论了浏览器如何将 HTML 和 CSS 转换为屏幕上的像素,并提到大多数浏览器通过五个步骤完成此操作。
可以将这五个步骤分成两部分来看。前一部分基本上是在构建计划:渲染器将 HTML 和 CSS 以及视口大小等信息结合起来,确定每个元素应该长成什么样(宽度,高度,颜色等)。最终得到的结果就是帧树 (frame tree),又称作渲染树(render tree)。
另一部分是绘制与合成(painting and compositing),这正是渲染器的工作。渲染器将前一部分的结果转换成显示在屏幕上的像素。

对同一个网页来说,这个工作不是只做一次就够,而必须反复进行。一旦网页发生变化(如某个 div 发生切换 ),浏览器需再次经历这当中的很多步骤。

即便页面并未发生变化(如页面滚动,或某些文本高亮),浏览器仍需进行第二部分中的某些步骤,接着在屏幕上绘制新的内容。

想要滚动、动画等操作看起来流畅,必须以 60 帧每秒的速度进行渲染。
每秒帧数(FPS)这个术语,也许你早有耳闻,但可能不确定其意义。想象你手上有一本手翻书(Flip Book)。一本画满静态绘画的书,用手指快速翻转,画面看起来就像动起来了。
为了使这本手翻书的动画看起来平滑,每秒需要翻过 60 页。
这本书的是由图纸制成的。纸上有许许多多的小方格,每个方格只能填上一种颜色。
渲染器的工作就是给图纸中的方格填色。填满图纸中的所有方格,一帧的渲染就完成了。
当然,计算机当中并不存在真实的图纸。而是一段名为帧缓冲区(frame buffer)的内存。帧缓冲区中的每个内存地址就像图纸中的一个方格...它对应着屏幕上的像素。浏览器将使用数字填充每个位置,这些数字代表 RGBA(红、绿、蓝以及 alpha 通道)形式的颜色值。

当显示器需要刷新时,将会查询这一段内存。
多数电脑显示器每秒会刷新 60 次。这就是浏览器尝试以每秒 60 帧的速度渲染页面的原因。这意味着浏览器有16.67 ms 的时间来完成所有工作(CSS 样式,布局,绘制),并使用像素颜色填充帧缓冲区内存。两帧之间的时间(16.67ms)被称为帧预算(frame budget)。
有时你可能听到人们谈论丢帧的问题。所谓丢帧,是系统未能在帧预算时间内未完成工作。缓冲区颜色填充工作尚未完成,显示器就尝试读取新的帧。这种情况下,显示器会再次显示旧版的帧信息。
丢帧就像是从手翻书中撕掉一个页面。这样一来,动画看上去就像消失或跳跃一样,因为上一页和下一页之间的转换页面丢失了。
因此要确保在显示器再次检查前将所有像素放入帧缓冲区。来看看浏览器以前是如何做的,后来又发生了哪些变化。从中可以发现提速空间。
绘制、合成简史
注意:绘制与合成是不同渲染引擎之间最为不同的地方。单一平台浏览器(Edge 和 Safari)的工作方式与跨平台浏览器(Firefox 和 Chrome)有所不同。
即便是最早的浏览器也有一些优化措施,使页面渲染速度更快。例如在滚动页面的时候,浏览器会保留仍然可见的部分并将其移动。然后在空白处中绘制新的像素。
搞清楚发生变化的内容,只更新变动的元素或像素,这个过程称为失效处理(invalidation)。
后来,浏览器开始应用更多的失效处理技术,如矩形失效处理(rectangle invalidation)。矩形失效处理技术可以找出屏幕中包围每个发生改变的部分的最小矩形。然后只需重绘这些矩形中的内容。
页面变化不大时,这确实能够减少大量工作。比如说,光标闪动。

但如果页面大部分内容发生变化,这就不够用了。所以又出现了处理这些情况的新技术。
图层与合成介绍
当页面的大部分发生变化时,使用图层(layer)会方便很多...至少在某些情况下是如此。
浏览器中的图层很像 Photoshop 中的图层,或手绘动画中使用的洋葱皮层。大体说来就是在不同图层上绘制不同元素。然后可以调整这些图层的相对层级关系。
这些一直以来就是浏览器的一部分,但并不总是用于加速。起初,它们只是用来确保页面正确呈现。它们对应于堆叠上下文(stacking contexts)。
例如一个半透明元素将在自己的堆叠上下文中。这意味着它有自己的图层,所以你可以将其颜色与下面的颜色混合。一帧完成后,这些图层就被丢弃。在下一帧中,所有图层将再次重绘。

但是,这些图层中的东西在不同帧之间常常没有变化。想一下那种传统的动画。背景不变,只有前景中的字符发生变化。保留并重用背景图层,效率会更高。
这就是浏览器所做的。它保留了这些图层。然后浏览器可以仅重绘已经改变的图层。在某些情况下,图层甚至没有改变。它们只需要重新排列:例如动画在屏幕上移动,或是某些内容发生滚动。
组织图层的过程称为合成。合成器(compositor)从这两部分开始:
源位图:背景(包括可滚动内容所占的空白框)和可滚动内容本身
目标位图:屏幕所显示的位图
首先,合成器将背景复制到目标位图中。
然后找到可滚动内容中应该展示的部分。将该部分复制到目标位图。

这减少了主线程的绘制量。但这意味着主线程需要花费大量时间进行合成。而还有很多工作在主线程上争夺时间。
以前我已经谈过这个问题,主线程有些像一个全栈开发者。它负责 DOM,布局和 JavaScript。并且还负责绘制与合成。

主线程花费多少毫秒进行绘制、合成,就有多少毫秒无法用于 JavaScript 和布局。

而另一部分硬件正在闲置,没有多少工作要做。这个硬件是专门用于图形的。它就是 GPU。自 90 年代末以来,游戏一直在使用 GPU 加速渲染帧。自那以后,GPU 日益强大。

GPU 加速合成
所以浏览器开发者开始把事情转移给 GPU 来处理。
有两项任务可以转交给 GPU:
1. 图层绘制
2. 图层合成
将绘制工作交给 GPU 可能比较棘手。所以在多数情况下,跨平台浏览器依然通过 CPU 进行绘制。
但 GPU 可以很快完成合成工作,转移过来比较简单。

一些浏览器在这种并行方法上走得更远,直接在 CPU 上添加了一个合成器线程。由它管理 GPU 中发生的合成工作。这意味着如果主线程正在执行某些操作(如运行 JavaScript),则合成器线程仍然可以处理其他工作,如在用户滚动时滚动内容。

这样就将所有合成工作从主线程中移出。尽管如此,它仍然在主线程上留下了大量的工作。图层需要重绘时,主线程需要执行绘制工作,然后将该图层转移给 GPU。
有些浏览器将绘制工作移动到另一个线程中(目前 Firefox 正致力于此)。但将绘制这点工作转移到 GPU 上,速度会更快。
GPU 加速绘制
因此,浏览器也开始将绘制工作转移到 GPU。

这项转变工作仍在进行中。一些浏览器一直通过 GPU 绘制,另一些浏览器只能在某些平台上(如 Windows 或移动设备)这么做。
GPU 绘制能够解决一些问题。CPU 得以解放,专心处理 JavaScript 和布局工作。此外,GPU 绘制像素比 CPU 快得多,因此它可以加快绘制速度。这也意味着从 CPU 复制到 GPU 的数据要更少了。
但是,在绘制与合成工作之间保持这种区分仍然会产生一定的成本,即使它们都在 GPU 上进行。这么区分,还限制了能够采用的优化类型,它们本可以使 GPU工作更快。
这就是WebRender 所要解决的问题。它从根本上改变了渲染方式,消除了绘制和合成之间的区别。这种解决渲染器性能的方法,能够在当下网络中提供最佳用户体验,并为未来网络提供最好的支持。
这意味着,我们要做的不仅仅是想使帧渲染更快...我们希望使渲染更加一致,不会发生闪动。即便有大量需要绘制的像素,如 4k 显示器或 WebVR 设备,我们仍希望体验能够平滑一些。
当前的浏览器何时会发生闪动 ?
在某些情况下,上述优化能够加速页面渲染。当页面上没有太多变化时(如只有光标在闪烁),浏览器将进行尽量少的工作。

将页面分成图层,增加了这种优化的收益(扩大了最佳情形数)。绘制数个图层,并让它们相对于彼此移动,则“绘画+合成”架构效果非常好。
但图层的使用也需要有所权衡。这将占用不少内存,实际可能会减慢工作。浏览器需要组合有意义的图层。但是很难区分怎样是有意义的。
这意味着,如果页面中有很多不同的东西在移动,图层可能会过多。这些图层占满内存,需要花费很长时间才能传输到合成器。

另一些时候,需要多个图层时,却可能只得到一个图层。这个图层将会不断重绘并转移到合成器,进行合成工作而不改变任何东西。
这意味着你已经将绘制量翻了一番,每个像素都处理了两遍,毫无益处。跨过合成这一步,直接渲染页面会更快。

还有很多情况下,图层用处不大。如对背景色使用动画效果,则整个图层都必须重绘。这些图层只对少量的 CSS 属性有用。
即使大部分帧都是最佳情形(也就是说,它们只占用了帧预算的一小部分), 动作仍可能不稳定。只要三两帧落入最坏情况,就会产生可感知的闪动。

这些情况称为性能悬崖(performance cliffs)。应用程序一直平稳运行,直到遇到这些最坏情况(如背景色动画),帧率瞬间濒临边缘。

不过,这些性能悬崖是可以规避的。
如何做到这一点呢?紧随3D 游戏引擎的脚步。
像游戏引擎一样使用 GPU
如果停止尝试猜测需要什么图层呢?如果不考虑区分绘制与合成,仅考虑每一帧绘制像素呢?
这听起来似乎很荒谬,但实际有先例可循。现代视频游戏重新绘制每个像素,并且比浏览器更可靠地保持每秒 60 帧。他们以一种意想不到的方式做到了这一点...他们只是重绘整个屏幕,无需创建那些用于最小化绘制内容的失效处理矩形和图层。
这样渲染网页不会更慢吗?
如果在 CPU 上绘制的话,的确会更慢。但 GPU 就是用来做这事的。
GPU 正是用于极端并行处理的。我在上一篇关于 Stylo 的文章中谈到过并行的问题。通过并行,机器可以同时执行多种操作。它可以一次完成的任务数量,取决于内核数量。
CPU 通常有 2 到 8 个内核。GPU 往往至少有几百个内核,通常有超过 1,000 个内核。
虽然这些内核的工作方式有所不同。它们不能像 CPU 内核那样完全独立地运行。相反,它们通常一起工作,在数据的不同部分执行相同指令。

填充像素时, 我们正需要这样。每个像素可以由不同的内核填充。一次能够操作数百个像素,GPU 在像素处理方面上比 CPU 要快很多...当所有内核都在工作时确实如此。
由于内核需要同时处理相同的事情,因此 GPU 具有非常严格的步骤,它们的 API 非常受限。我们来看看这是如何工作的。
首先,你需要告诉 GPU 需要绘制什么。这意味着给它传递形状,并告知如何填充。
要达到目的,首先将绘图分解成简单形状(通常是三角形)。这些形状处于 3D 空间中,所以一些形状可以在其他形状背后。然后将三角形所有角顶点的 x、y、z 坐标组成一个数组。
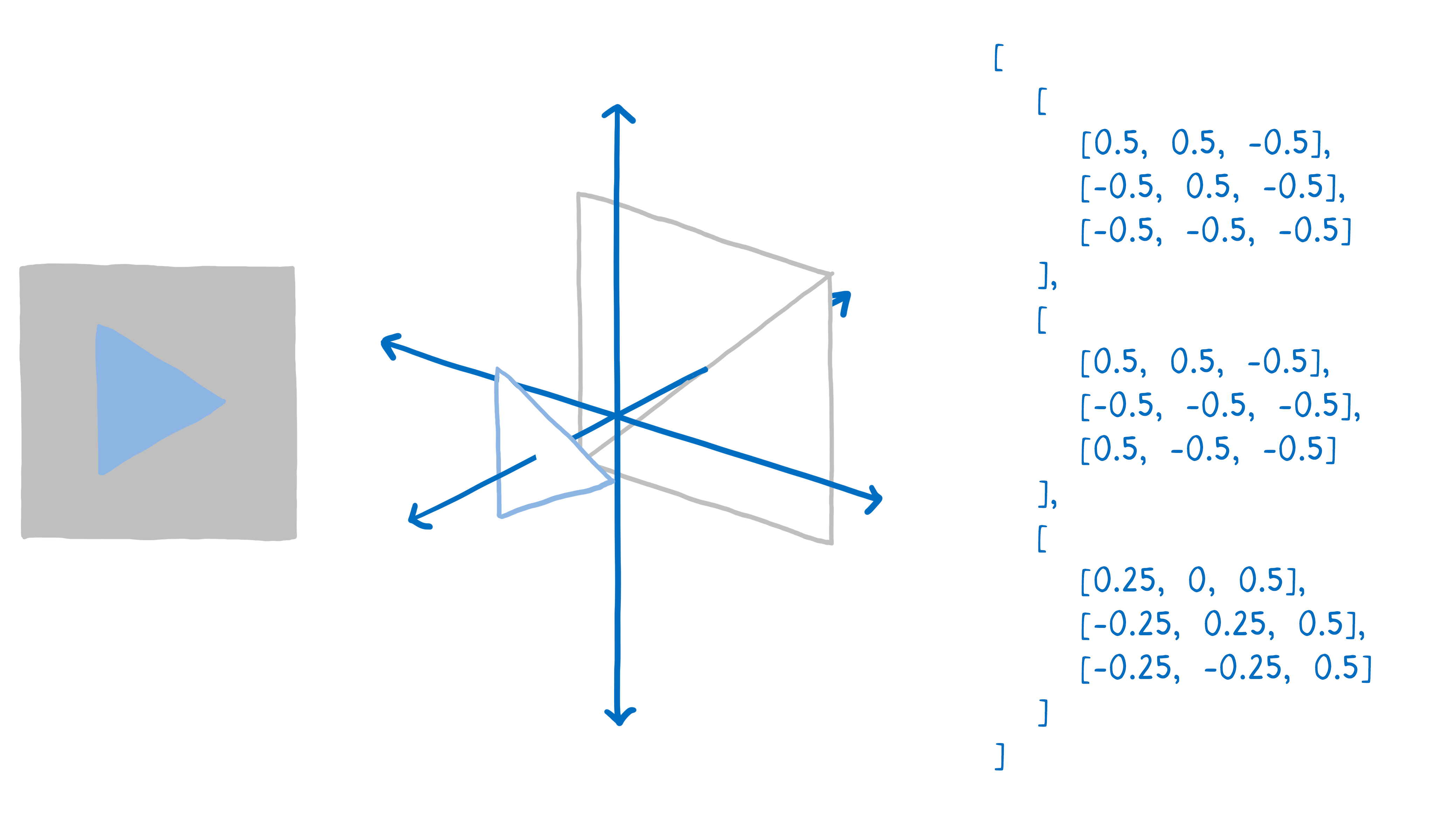
然后发出一个绘图调用 —— 告诉GPU来绘制这些形状。

接下来由 GPU 接管。所有的内核将同时处理同一件事情。它们会:
- 找到形状的所有角顶点位置。这被称为顶点着色(vertex shading)。

- 找出连接这些角顶点的线条。由此可以得到哪些像素被形状所覆盖。这就是所谓的光栅化(rasterization)。

- 已经知道形状所覆盖的像素了,就可以遍历每个像素,确定该像素的颜色。这称为像素着色(pixel shading)。

最后一步可以通过不同的方式完成。要告诉 GPU 如何处理,可以传给 GPU 一个称为像素着色器的程序。像素着色是 GPU 中可编程的几个部分之一。
一些像素着色器很简单。例如形状是单一颜色的,则着色器程序只需要为形状中的每个像素返回同一个颜色。
另外一些情况更复杂,例如有背景图像的时候,需要搞清楚图像对应于每个像素的部分。可以像艺术家缩放图像一样…在图像上放置一个网格,与每个像素相对应。这样一来,只需知道某个像素所对应的区域,然后对该区域进行颜色取样即可。这被称为纹理映射(texture mapping),因为它将图像(称为纹理)映射到像素。

针对每个像素,GPU 会调用像素着色器程序。不同内核可以同时在不同的像素上并行工作,但是它们都需要使用相同的像素着色器程序。命令 GPU 绘制形状时,你会告诉它使用哪个像素着色器。
对几乎所有网页来说,页面的不同部分将需要使用不同的像素着色器。
在一次绘制中,着色器会作用于所有形状,所以通常需要将绘制工作分为多个组。这些称为批处理(batches)。为了尽可能利用所有内核,创建一定数量的批处理工作,每个批次包括大量形状。

这就是 GPU 如何在数百或数千个内核上切分工作的。正是因为这种极端的并行性,我们才能想到在每一帧中渲染所有内容。即便有这样极端的并行性,要做的工作还是很多。解决起来还需要费些脑筋。该 WebRender 出场了……
WebRender 如何利用 GPU
回过头再看下浏览器渲染网页的步骤。这里将产生两个变化。

1. 绘制与合成之间不再有区别。它们都是同一步骤的一部分。GPU 根据传递给它的图形 API 命令同时执行它们。
2. 布局步骤将产生一种不同的数据结构。之前是帧树(或 Chrome 中的渲染树)。现在将产生一个显示列表(display list)。
显示列表是一组高级绘图指令。它告诉我们需要绘制什么,并不指定任何图形 API。
每当有新东西要绘制时,主线程将显示列表提供给 RenderBackend,这是在 CPU 上运行的 WebRender 代码。
RenderBackend 的工作是将这个高级绘图指令列表转换成 GPU 需要的绘图调用,这些绘图调用被分在同一批次,加快运行速度。

然后,RenderBackend 线程将把这些批次传递给合成器线程,合成器线程再将它们传递给 GPU。
RenderBackend 线程传递给 GPU 的绘图调用需要尽可能快运行。它为此使用了几种不同的技术。
从列表中删除任何不必要的形状(早期剔除)
节省时间的最好办法是什么都不做。
首先,RenderBackend 可以减少显示列表项目。它会识别哪些项目将真正出现在屏幕上。为此,它将查看一些东西,如每个滚动盒的滚动距离。
如果形状的某些部分在盒子内,则该形状将被包括在需要绘制的列表中。否则将被删除。这个过程叫做早期剔除。

最小化中间纹理数量(渲染任务树)
现在有了一个树状结构,其中只包含将要用到的形状。这个树被组织成此前提过的堆叠上下文。
CSS filter 和堆叠上下文等这些效果,让事情变得复杂了。假设有一个透明度为 0.5 的元素,该元素包含子元素。你可能觉得每个子元素都将是透明的……但实际上整个组才是透明的。

因此需要先将该组渲染为一个纹理,每个子元素都是不透明的。然后,将子元素加入到父元素中时,可以更改整个纹理的透明度。
这些堆叠上下文可以嵌套...该父元素可能是另一个堆叠上下文的一部分。这意味着它必须被渲染成另一个中间纹理……
为这些纹理创建空间代价不菲。我们想尽可能将事物分组到相同的过渡期纹理。
为了帮助 GPU 执行此操作,需要创建一个渲染任务树。有了它,就能够知道在其他纹理之前需要创建哪些纹理。任何不依赖于其他纹理的纹理都可以在首次创建,这意味着它们可以与那些中间纹理中组合在一起。
所以在上面的例子中,我们先输出 box shadow 的一个角。(实际比这更复杂一点,但这是要点)。

第二遍的时候,可以将这个角通过镜像放置到盒子的各个部分。然后就可以完全不透明地渲染该组。

接下来,我们需要做的就是改变这个纹理的不透明度,并将其放在需要输入到屏幕的最终纹理中。

通过构建这个渲染任务树,可以找出需要使用的离屏渲染目标的最小数量。这很好,前面已经提到过,为这些渲染目标纹理创建空间的代价不菲。
这也有利于分批处理。
绘制调用分组(批处理)
前面已经提到过,需要创建一定量的批处理,每个批处理中包括大量形状。
注意,创建批处理的方式真的能影响速度。同一批次中的形状数量要尽可能多。这是由几个原因决定的。
首先,当 CPU 告诉 GPU 进行绘图调用时,CPU 必须做很多工作。比如,启动 GPU,上传着色器程序和测试硬件 bug 等。并且当 CPU 进行这项工作时,GPU 可能是空闲的。
其次,改变状态是会产生代价的。假设你需要在批处理之间更改着色器程序。在典型的 GPU 上,你需要等到所有内核都使用当前的着色器完成工作后。这被称管道清空(draining the pipeline)。管道清空后,其他核心才会处于闲置状态。

因此,批处理包含的东西要尽可能多。对于典型的 PC,每帧需要有100 次或更少的绘图调用,每次调用中有数千个顶点。这样就能充分利用并行性。
从渲染任务树可以找出能够批处理的内容。
目前,每种类型的图元都需要一种着色器。例如边框着色器,文本着色器,图像着色器。

我们认为可以将很多着色器结合起来,这样就能够增加批处理容量。但目前这样已经相当不错了。
已经可以准备将它们发送给 GPU 了。但其实还可以做一些排除工作。
减少像素着色(Z-剔除)
大多数网页中都有大量相互重叠的形状。例如,文本框位于某个带有背景的 div 之中,而该 div 又在带有另一个背景的 body 中。
GPU 在计算每个像素的颜色时,能够计算出每个形状中的像素颜色。但只有顶层才会显示。这被称为 overdraw,它浪费了 GPU 时间。

所以我们可以先渲染顶部的形状。绘制下一个形状时,遇到同一像素,先检查是否已经有值。如果有值,则跳过。

不过这有一点点问题。当形状是半透明的时候,需要混合两种形状的颜色。为了让它看起来正确,需要从里向外绘制。
所以需要把工作分成两道。首先做不透明的一道工作。由表及里,渲染所有不透明的形状。跳过位于其他像素背后的像素。
然后处理半透明形状。工作由内向外进行。如果半透明像素落在不透明像素的顶部,则会混合到不透明的像素中。如果它会落在不透明形状之后,则忽略计算。
将工作分解为不透明和 alpha 通道两部分,跳过不需要的像素计算,这个过程称为 Z-剔除(Z-culling)。
这看起来只是一个简单的优化,但对我们来说已经是很大的成功了。在典型的网页上,该工作大大减少了我们需要处理的像素数量,目前我们正在研究如何将更多的工作转移到不透明这一步。
到目前为止,我们已经准备好了一帧的内容。我们已经尽可能地减少了工作。
准备绘制
我们准备好启动 GPU 并渲染各个批次了。

警告:不是一切都靠 GPU
CPU 仍然需要做一些绘制工作。例如,我们仍然使用 CPU 渲染文本块中的字符(称为字形,glyphs)。在 GPU 上也可以执行此操作,但是很难获得与计算机在其他应用程序中呈现的字形相匹配的像素效果。所以 GPU 渲染的字体看起来会有一种错乱感。我们正在尝试通过 Pathfinder 项目将字形等工作转移到 GPU 上。
这些内容目前是被 CPU 绘制成位图的。然后把它们上传到 GPU 的纹理缓存中。这个缓存在不同帧之间被保留,因为它们通常不会改变。
虽然这种绘制工作是由 CPU 完成的,但速度仍有提升空间。例如,使用某种字体绘制字符时,我们会将不不同的字符分割开,使用不同内核分别渲染。这和Stylo 用来并行计算样式的技术是相同的……参见这里。
WebRender 接下来的工作
在 Firefox Quantum 发布之后的若干版本后,WebRender 有望在 2018 年作为Quantum Render 项目的一部分,出现在 Firefox 中。这将使当今的网页运行更顺畅。随着屏幕上的像素数量的增加,渲染性能变得越来越重要,因此 WebRender 还可以让 Firefox 为新一波的高分辨率 4K 显示器做好准备。
但 WebRender 不仅仅适用于 Firefox。它对于正在开展的 WebVR 的工作同样至关重要,在 WebVR 中,需要为在 4K 显示器上以 90 FPS 的速度为每只眼睛渲染不同的帧。
WebRender 的早期版本目前可以通过 Firefox 的 flag 来启用。集成工作仍在进行中,所以性能目前还不如集成工作完成后那么好。如果你想跟进 WebRender 开发,可以关注GitHub repo,或者关注Firefox Nightly 的Twitter,以获得 Quantum Render 项目的更新周报。
关于作者
Lin 是 Mozilla 开发者关系团队的工程师。她在鼓捣 JavaScript,WebAssembly,Rust 和 Servo,以及绘制代码漫画。